Tangled in the Threads
Jon Udell, September 6, 2000The Art of Organizing Search Results
I'm often asked the question: "What's the best search engine?" When "best" means "easiest-to-use" then nowadays, my answer is usually Atomz. It's a hosted service, free for sites with fewer than 500 pages, which requires hardly any special skills to set up and use.
What does require some thought, and some skill, is the process of usefully organizing the results that come back from Atomz -- or indeed, from any other search engine. The web is full of sites that make no effort to design their search-results pages. I don't just mean applying a templated style to the default Atomz or Excite or Verity or Microsoft result pages. Nor do I mean simply ordering results by relevance, which begs the question: relevant to whom, and for what? Rather, I mean a deep reorganization of the result set, which both reflects and adapts to the underlying information architecture of the site. Search engines can't do this for you. The task involves some or all of these things:
-
Discovering, and exploiting, metadata patterns implicitly present in the site.
-
Managing the site's content in a way that creates explicit metadata patterns.
-
Extracting metadata from search results.
-
Transforming the metadata into new, more useful shapes.
-
Converting the metadata into HTML, for delivery to the browser.
-
Possibly, converting the metadata into XML, for delivery to downstream components.
My first experience with this procedure yielded the search-results page for an earlier incarnation of this site:
BYTE.com search results, circa 1997
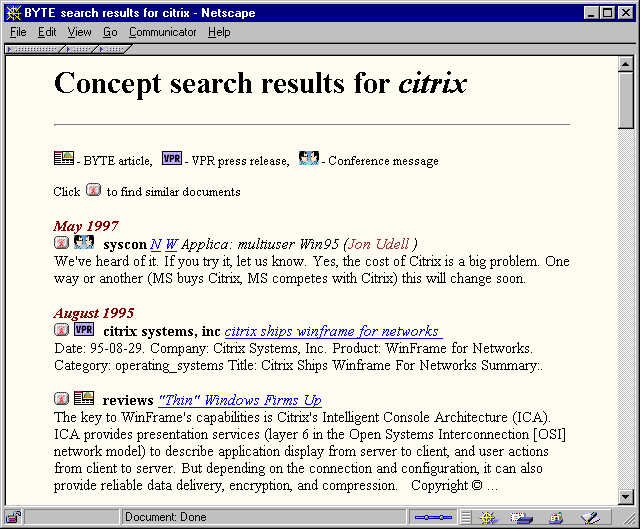
In this example, results are grouped by month. Within each group, icons are used to indicate three different datatypes -- newsgroup messages, press releases, and BYTE articles. A boldfaced element, which secondarily characterizes each entry, is drawn from an appropriate piece of metadata for each datatype: the newsgroup's name, the company that submitted the press release, the magazine department in which the article appeared.
How to find (or create) and exploit metadata patterns to achieve this result is a subject that's covered in chapter 8 of my book, and you can find the code on the examples page. More recently, I've used this technique to reorganize stock search results on two other sites: www.oreilly.com, and www.linux-mag.com. For O'Reilly, I'm working as a consultant on a forthcoming online books site called Safari, and in that context have been helping to refine the book searching at oreilly.com. For Linux Magazine, I'm the webmaster. Both sites happen to use Atomz, which I heartily recommend, but that's unrelated to my message in this column. As I'll show, the name of this game is to manage, and transform, metadata. And at the appropriate level of abstraction, all search engines deal with the same stuff: URLs, document titles, and blurbs.
O'Reilly search, before and after
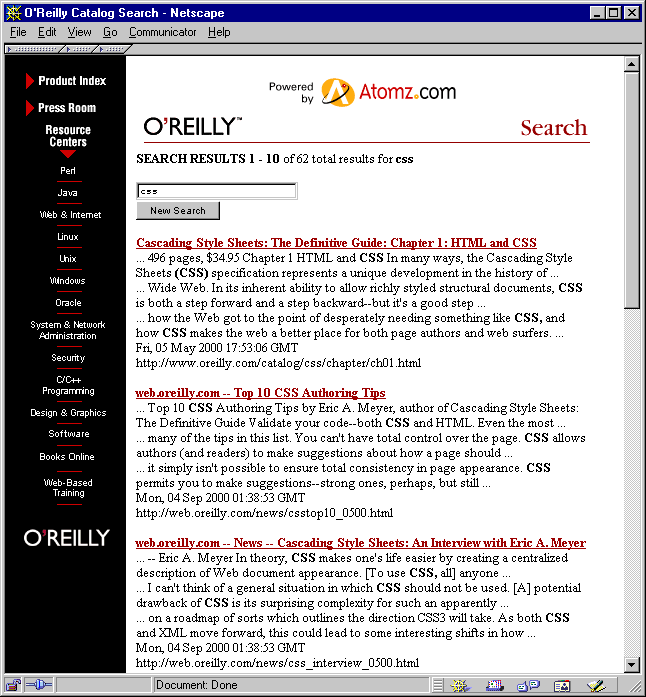
From an info-architecture perspective, oreilly.com serves up two types of search result: books in the catalog, and articles in subsites such as perl.oreilly.com and web.oreilly.com. The stock Atomz search report does not, and cannot, distinguish between these types. It just lists results, from most "relevant" to least:
stock Atomz search results for oreilly.com
Here's an alternate presentation that answers, much more directly, the question "Which books in the catalog mention 'css'":
Atomz search results for oreilly.com, organized by book
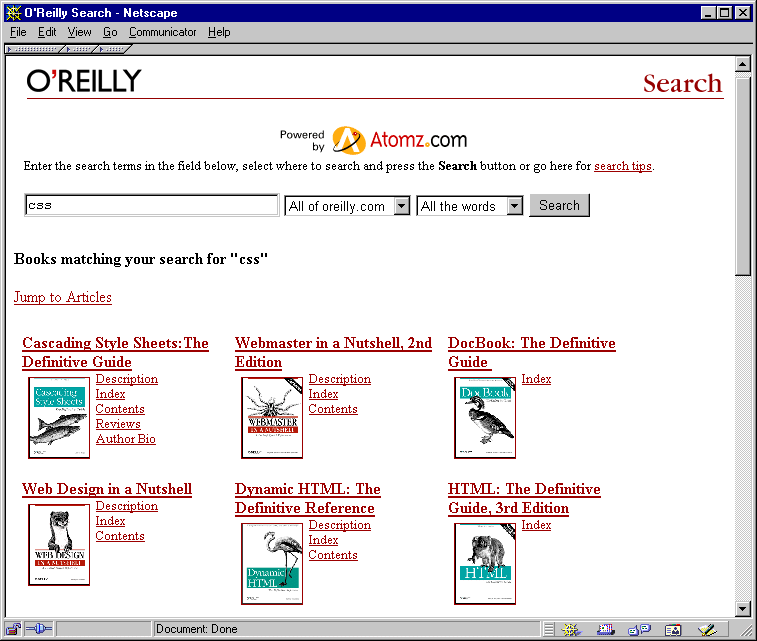
This version preserves the relevance ranking in the original result set. So here, as in the earlier example, Eric Meyer's Cascading Style Sheets shows up first. But in this version:
- Books that are scattered throughout the multi-page Atomz result set are consolidated into a single view.
- An image of a book cover iconically represents each book, and links to its main catalog page.
- Other pages related to each book are displayed next to its cover image.
You could (and I did) accomplish this transformation without any administrative access to the oreilly.com site. Everything needed was available by way of Web APIs. Interestingly, the site's webmaster, Allen Noren, did not even realize that he had been creating APIs. And in a formal sense, he had not been doing so. You can't (today) issue an XML-RPC or SOAP call to the site, querying for lists of books and for associated per-book metadata. But Allen assured that the metadata would nevertheless be available by organizing the site according to strict naming conventions. For example, the primary URL for every book in the catalog follows this pattern:
www.oreilly.com/catalog/NICKNAMEwhere NICKNAME is a short mnemonic term. You can always append "/desc.html" to the pattern to obtain the description of the book. And you can always form the URL of a cover image using this pattern:
search.oreilly.com/catalog/covers/NICKNAME.s.gifFinally, you can derive a complete list of nicknames, and corresponding titles, from the main catalog page.
Many people think that you need fancy content management systems, or a fully XML-ized site architecture, to achieve the effects illustrated here. It simply isn't true. There are certainly huge benefits to be had from CMS and XML technologies, but they're no substitute for good old-fashioned common sense. What Allen Noren did instinctively (and inexpensively) created a framework of metadata, and an implicit API. Making that API explicit is a job for a first-class scripting language that can absorb text into data structures, rearrange those structures, and emit new text. In this case I used Perl, though Python or another language could easily do the same job.
There is, to be sure, a role for XML here. Actually, there are several. First, although my script can easily "screen-scrape" Atomz's HTML output, you can ask Atomz to emit search results that are packaged as XML. Although this can be useful, it's important to remember that XML isn't magic pixie dust, and doesn't in and of itself mean anything. When you see a date represented like this:
<ATOMZ-SEARCH-DATE> Sun, 03 Sep 2000 04:54:49 GMT </ATOMZ-SEARCH-DATE>it's easy to be dazzled by the angle brackets. But in fact, the date reported this way -- the last-modifed date of the found HTML page -- may have nothing to do with the true publication date of the article. That information may reside, instead, in another piece of metadata. Often, for sites I run, it's a pseudo-field in the URL or HTML doctitle, as we'll see in the next section.
In practice, Atomz's XML mode is not all that important to me, because it doesn't represent any of the structural enhancements that I make when postprocessing the Atomz results. What is very interesting, though, is to pass those processed results along as XML for the convenience of downstream processes.
The oreilly.com search mechanism shown here is an interim step. Eventually the catalog-searching component of the site will be handled by Safari. And when that happens, Safari will offer an interface that returns packages of XML results. The first client of that interface will be oreilly.com, which will combine Safari book results with Atomz resource-center results. But any other site wishing to incorporate oreilly.com catalog search will be able to use the same XML interface.
Linux Magazine search, before and after
You can see another example of search-results postprocessing in these before and after examples from the Linux Magazine site. Here, there's only a single datatype: articles written for the magazine, or for the site. The postprocessor first builds an unordered list of hashtables containing the essential metadata for each search result:
Linux Magazine search results grouped by issue date
|
{
'title' => ' July 1999 | PRODUCT REVIEW | APACHE: The Definitive Guide, Second Edition', 'url' => 'http://www.linux-mag.com/1999-07/productreview_01.html', 'blurb' => ' ... version Linux Magazine / July 1999 / REVIEWS <b>APACHE:</b> The Definitive Guide, Second Edition PRODUCT REVIEW <b>APACHE:</b> The Definitive Guide, Second Edition by Elizabeth Zinkann With <b>Apache</b> being the most popular Web server platform in ... ' }, { 'title' => ' June 1999 | FEATURES | The Apache Story', 'url' => 'http://www.linux-mag.com/1999-06/apache_06.html', 'blurb' => ' ... Issues Feedback Contacts feedback mail to a friend printer-friendly version Linux Magazine / June 1999 / FEATURES The <b>Apache</b> Story << prev page 01 02 03 04 05 06 Again, IBM beat my expectations. I frankly didn\'t know what to expect ... ' }, |
From this unordered list, can produce two hashtables-of-lists (HoLs, in Perl-speak). One groups the results by issue date, like this:
Linux Magazine search results grouped by department
|
'1999-06' => [
{ title' => ' June 1999 | FEATURES | The Apache Story', 'url' => 'http://www.linux-mag.com/1999-06/apache_01.html', 'blurb' => ' ... Magazine / June 1999 / FEATURES The <b>Apache</b> Story page 01 02 03 04 05 06 next >> FEATURES The <b>Apache</b> Story by Rob McCool, Roy T. Fielding, and Brian Behlendorf The <b>Apache</b> HTTP Server Project <b>(http//www.apache.org/)</b> has become a ... ' }, { 'title' => ' June 1999 | GURU GUIDANCE | Running a Web Server under Linux', 'url' => 'http://www.linux-mag.com/1999-06/guru_01.html', 'blurb' => ' ... Open Source <b>Apache</b> Web server by default. Someone recently asked me to help them install a Web server on her Linux system. I simply pointed her Web browser at http:// localhost, and up came a "Test Page" from Red Hat\'s <b>Apache</b> ... ' }, ... |
In this case, the date (e.g., 1999-06) is a piece of a managed URL. Another source of the same metadata is the doctitle -- that is, the HTML <TITLE> tag. Note that the "last-modified" date returned by the Web server will almost always be wrong, because this site is dynamically generated.
I like to use structured doctitles -- such as "June 1999 | FEATURES | The Apache Story" -- as a kind of virtual metadata store. One advantage, as compared to other ways of embedding metadata, is that the doctitle is aways available on the surface of the results page produced by any engine. You don't have to dig into the underlying page to get access to this metadata.
The other view groups results by magazine department, like this:
|
'FEATURES' => [
{ 'title' => ' June 1999 | FEATURES | The Apache Story', 'url' => 'http://www.linux-mag.com/1999-06/apache_01.html', 'blurb' => ' ... Magazine / June 1999 / FEATURES The <b>Apache</b> Story page 01 02 03 04 05 06 next >> FEATURES The <b>Apache</b> Story by Rob McCool, Roy T. Fielding, and Brian Behlendorf The <b>Apache</b> HTTP Server Project <b>(http//www.apache.org/)</b> has become a ... ' }, { 'title' => ' April 2000 | FEATURES | Apache Power', 'url' => 'http://www.linux-mag.com/2000-04/behlendorf_01.html', 'blurb' => ' ... Linux Magazine / April 2000 / FEATURES <b>Apache</b> Power page 1 2 3 4 next >> FEATURES <b>Apache</b> Power Brian Behlendorf\'s work on <b>Apache</b> helped keep the Web free. Now he wants to take open source development to the next level. by Robert ... ' }, ... |
Here, a "pseudo-field" of the HTML doctitle is the only available metadata hook. Managing the set of doctitles on your site is an easy, cheap, and powerful information-architecture strategy, but one that's all too often overlooked. It's vital for postprocessing, as seen here. It's also a great way to brand your search results -- as served by any public search engine -- with a consistent look, and to ensure those results will be wrapped in the maximum amount of useful context.
Given these data structures, it's trivial to generate corresponding HTML. The trick is getting the search results into a raw structure, then transforming them usefully. Some really low-tech data management procedures can ensure that this extraction and transformation will be easy too. I wish more sites took the trouble to do this. The results that a search engine delivers are just raw material. The engine can't figure out the best way to shape that material. Only you can do that.
Jon Udell (http://udell.roninhouse.com/) was BYTE Magazine's executive editor for new media, the architect of the original www.byte.com, and author of BYTE's Web Project column. He's now an independent Web/Internet consultant, and is the author of Practical Internet Groupware, from O'Reilly and Associates. His recent BYTE.com columns are archived at http://www.byte.com/index/threads
